Lesson 4: Practical Example
Using Jupyter Notebook
Jupyter Notebook is a web-based environment that is divided into cells, with each cell containing executable code.
To use Jupyter Notebook on Kaggle, you must first either create a new notebook or collaborate on one that has already been created. By using the Edit button at the top-right of the page, you can add or remove code or markdown text, run a selection of code, or run entire notebooks. The output will be printed inline within the notebook for easy accessibility. Notebooks can be private to a certain group of people, or they can be public to share with all users of the Kaggle site.
Analysing the Spotify dataset
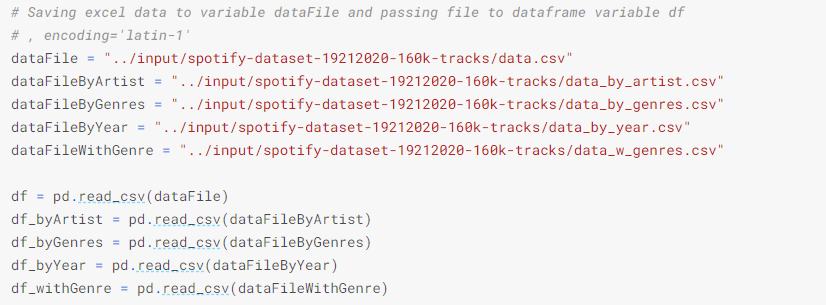
At the start of each notebook, it is a good practice to include all the Python libraries that will be needed during the data preparation, understanding, and interpretation stages. As we see in this example, the main software library for data manipulation and analysis is pandas, which is written in Python. To visually represent the data, we have also imported the matplotlib and seaborn libraries.
In this initial section, we have also set up our variables. These variables act as storage locations, memory references, or a symbolic name and they each contain a value. As we can see in this instance, that value is each of the specific .csv files, followed by a method to call and read these files within the notebook.
To run the sample Jupyter Notebook, click Edit and either click run on each section of code or Run All to run all the code from the beginning.
When we have a dataset (this could be a Microsoft Excel file that is saved as a .csv file), these are rarely clean and ready-made for analysis. Before diving into a dataset, it is important to clean it. This involves correcting human errors, adding missing values, or correcting irregular cardinalities, where there are multiple entries referring to the same value (m, M, male, Male, Man, and so on).
After the dataset has been cleared, we can go to the next stage, which is the Data Interpretation stage. In this section, we can use the pandas library to better understand what the values tell us about our dataset.
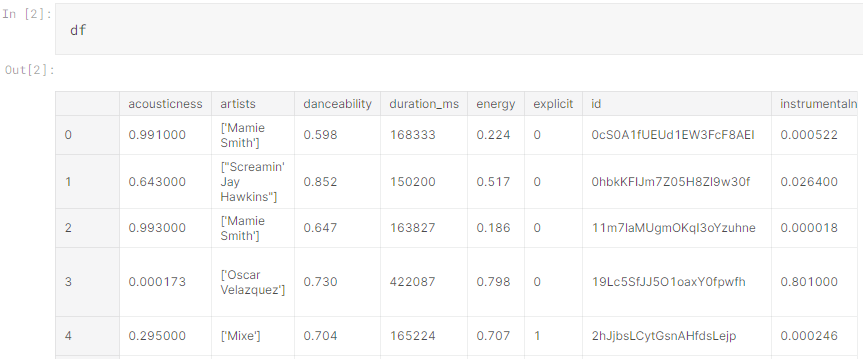
Basic examples of this might be to understand how many rows there are in the dataset. In the below example, first we have a list of all our variables. When we call df, it uses a pandas function to read the .csv file that we give it (dataFile in this instance). Calling it prints the entire dataset. The columns are our features and are highlighted in bold on the x-axis. On the y-axis, we can see numbers which represent each cell in the dataset.
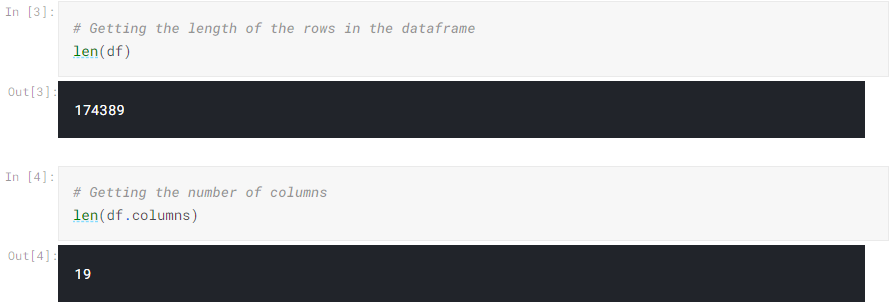
We can pass a different function to the df variable so that we can understand the dataset. In the below example, we can use the len function to see how many rows are in the dataset. In the second example, we can use the dot-notation to access the columns only. In the below example, we can see that there are 19 columns, which are our 19 features.
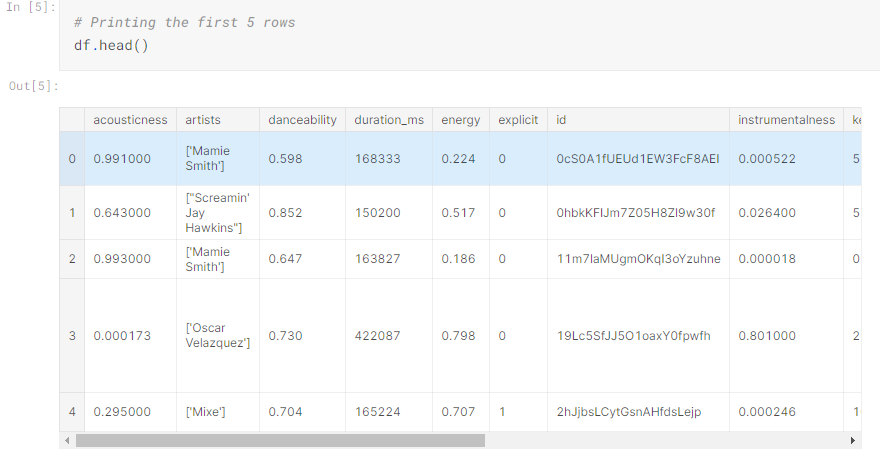
We can used the dot-notation to also view a subset of the complete dataset. As in the example below, we can call the .head() function on our variable df. In programming, head refers to the top section of a file. In this instance, head returns the first five cells from the dataset. The reverse of this is the .tail() function which returns the final five cells in a dataset.
When it comes to the Data Interpretation stage and we need to understand what the statistics tell us about the dataset, it is important to ensure that each column (or feature) is set to the correct datatype so that the statistics are accurate. There are two main types of features in a dataset: categorical and continuous features.
- Categorical data refers to data that can be divided into categories and should be given a datatype of category. Sometimes there are values that may fall in between these two datatypes. An example of this would be an ID. While an ID may be a numerical value, from a statistical point of view, that would not tell us anything about the data because the number is a sort of placeholder in this case. Similar, an ID is not something that can be categorised, as in the case where you have 174,000+ rows (as in this instance); each would be unique because IDs are unique. It would not be practical to categorise each of these IDs. In this instance, where category or continuous is not possible, we would assign that feature a datatype of “object”.
- Continuous features refer to any sort of numerical data. Depending on how many decimal places are required for accuracy, a continuous datatype would normally be integers (int64) or floats (float64).
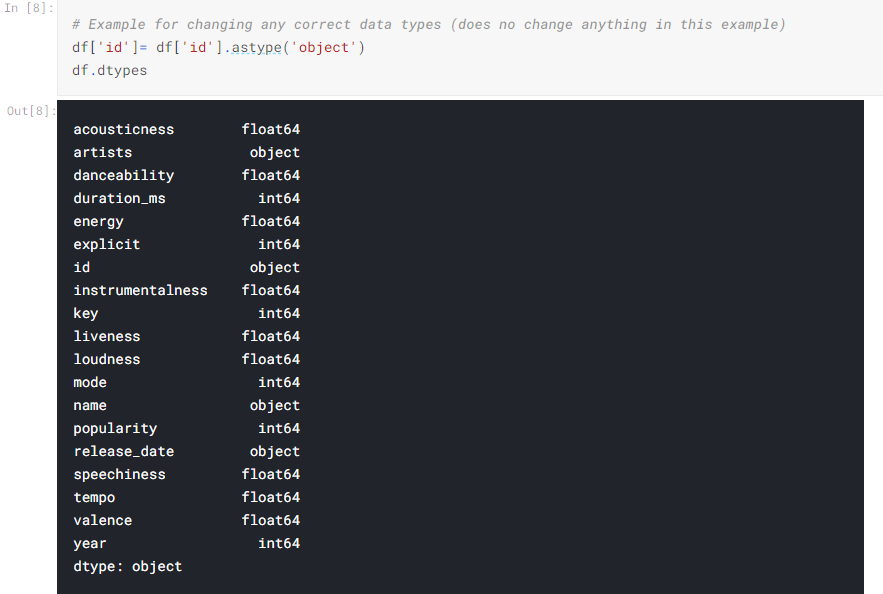
When it comes to cleaning the data, it may be determined that the object datatype may not be valuable in understanding a dataset. Until that determination is made, they should be assigned this datatype rather than be removed.
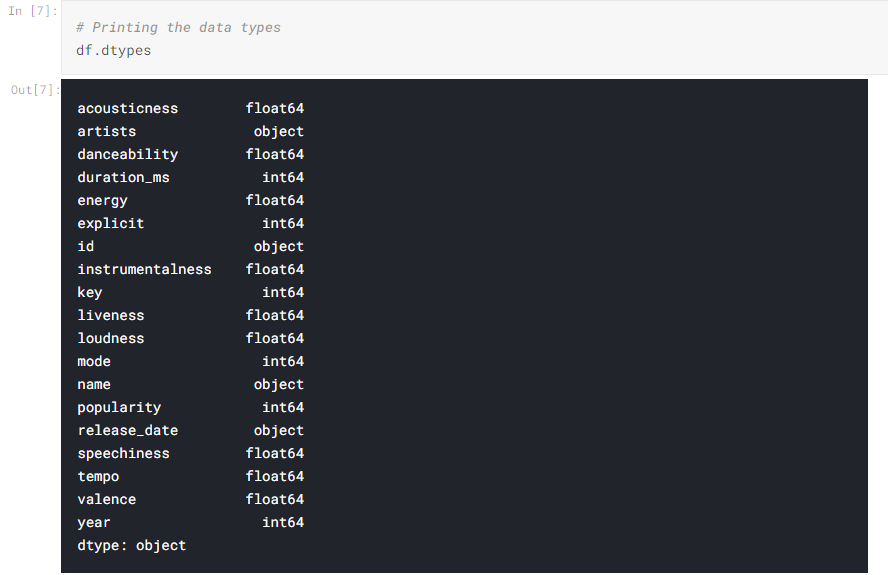
Taking what we have seen from the previous sections, below is an example where we create a variable called category_columns. The information that we are assigning to that variable is first, accessing the df. Next, we use the select_dtypes() function to gather our information based only on the datatype. In this instance, we are looking for information about any feature that has a datatype of Object, and we use the dot-notation to get those columns (features).
After this, we pass what we gather in category_columns and use the describe().T function to perform some statistical analysis. In this instance, artists, ID, name, release_date have a datatype of object so these are gathered. From these features we can see the count of the rows, how many unique values there are, what the top occurrence is, and that frequency.
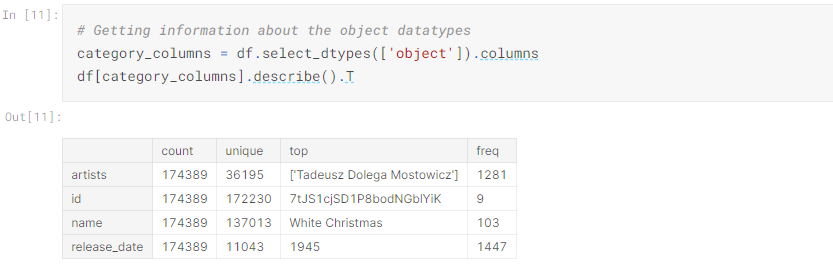
When we move to start cleaning the data, there are three factors we consider, as we mentioned above: human errors and irregular cardinality, missing values, and outliers. In the example below, we are checking for where a row has null or 0 values. This might be because a value was not available and was auto filled with null incorrectly. Null values can skew our interpretation of the statistics, and it is important to clean these if there are too many. Below, we can see an example where we call our “df” variable as before, along with the .isnull() function to check if values are null, and we sum these values with .sum(). We can see in this example that there are no null values which are good.
Data Preparation (Cleaning)
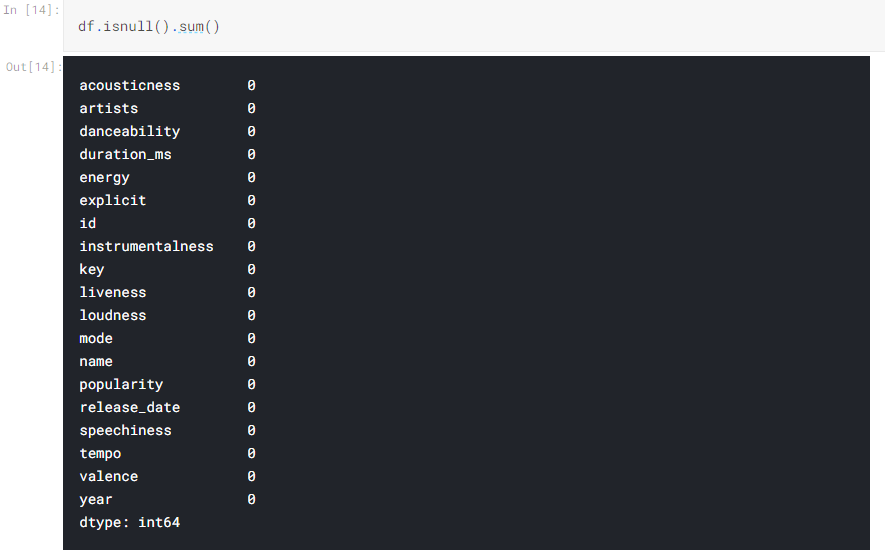
When cleaning the dataset, one of the first things that we would do is adjust and incorrect datatypes, as we discussed in the Data Exploration and Understanding section. In this instance, the datatypes are already correct. Below is an example where we take the feature “id”. If this feature was set as a continuous feature such as “int64” before cleaning, we would need to correct this so that our statistics in the Data Interpretation section are not skewed. The below example uses our “df” variable, which contains the entire dataset, and narrows this down to “id” only. From there, we create a new version of the “id” feature by editing it with the .astype() function. In this example, we edit it to reflect as an “object” datatype. We run a new version of the list of datatypes and can see that id is correctly set as object.
Equally important is to drop duplicate rows within a dataset. If entire rows are the same, they will not tell us anything new about the dataset, but may skew the statistics by inflating them. In the example below, we use the drop_duplicates() function on the variable “df”, which contains the entire dataset. This will indentify and drop any duplicate rows.
To confirm this, we can compare the number of rows that were first identified in the Data Exploration and Understanding stage with the number of rows that are dispalyed after we run the below command:
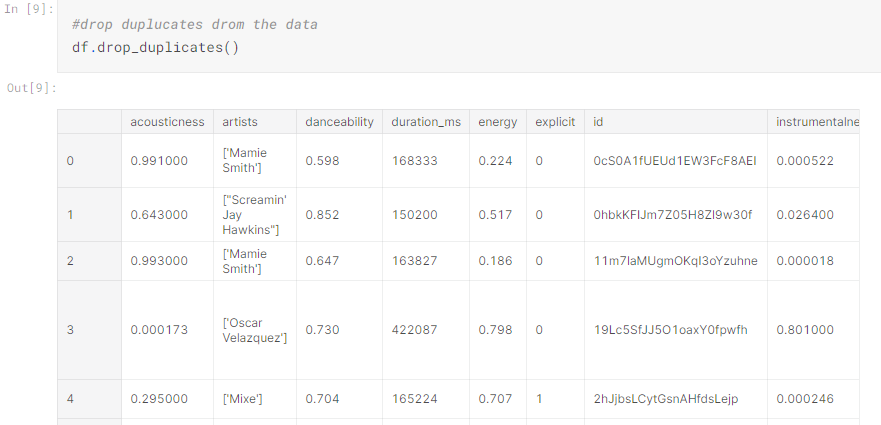
Data Interpretation
Now we can analyse the data using various built-in methods.
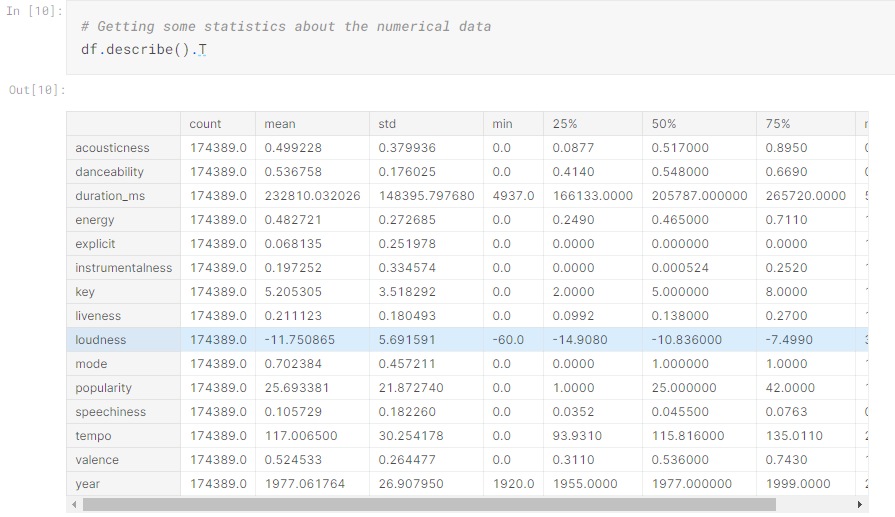
More examples are available on Kaggle.
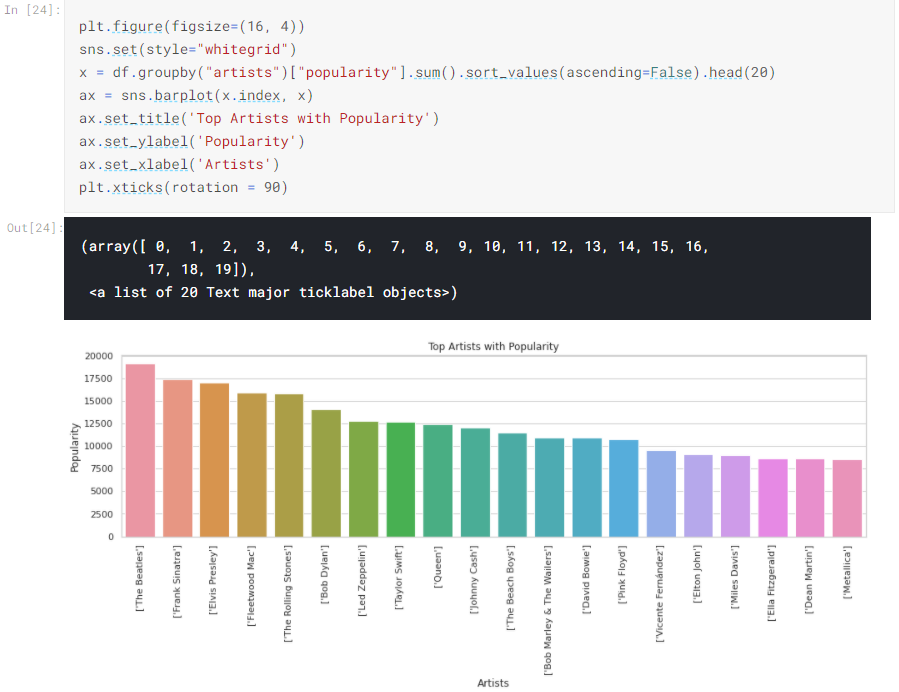
We can generate some charts (note that this code generates more charts than are shown here):
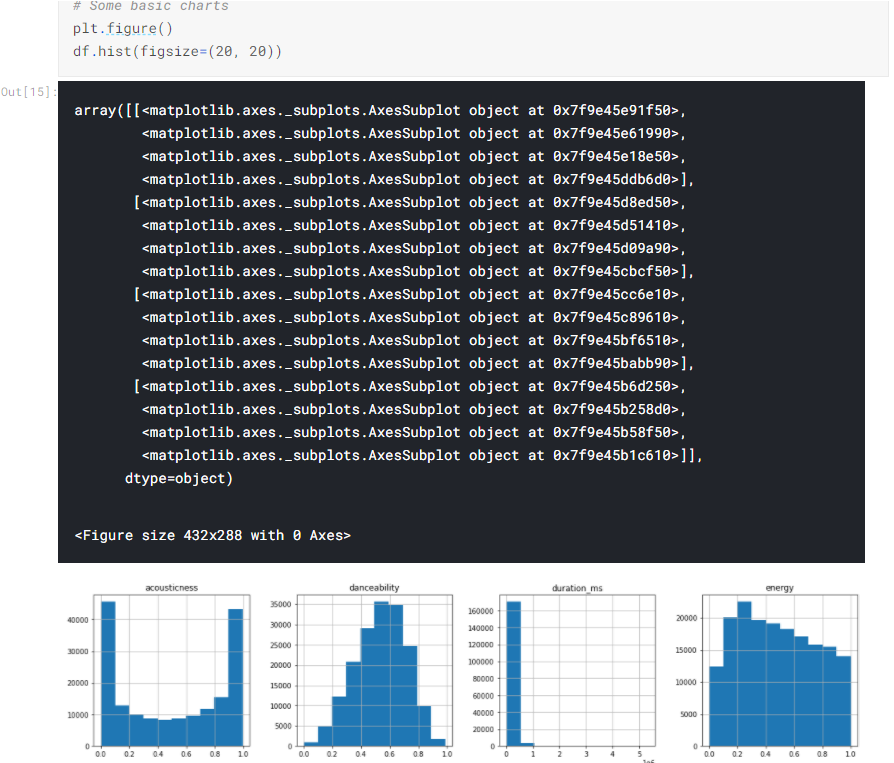
We can create other types of chart, for example:
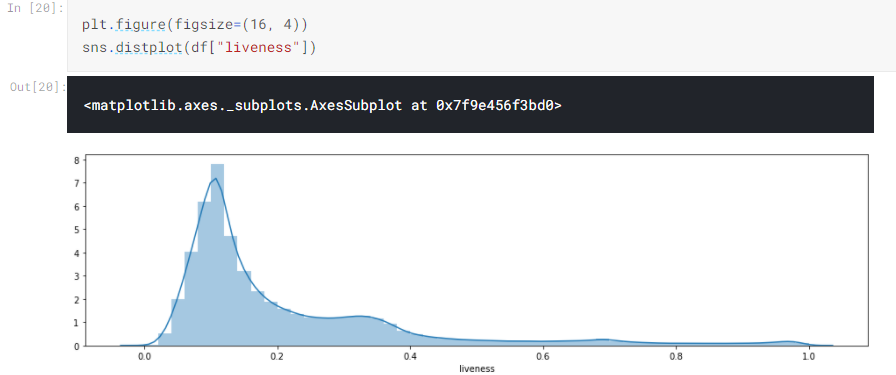
Or
Go to the Kaggle.com site yourself and see other charts that can be made and other data that you can analyse.